Yes, Randoli runs a lightweight data plane in your environment. But this is a feature, not a burden. With Datadog and Dynatrace, you still end up managing:
- Archival storage (for compliance)
You’re already paying for long-term storage separately anyway. Randoli simply:
- Processes data locally (reducing egress and ingestion costs by up to 90%)
- Keeps your architecture aligned with modern cloud-native patterns
- Uses a lightweight, auto-managed agent with minimal overhead
The net result? Lower total cost, better control, and no surprise bills.
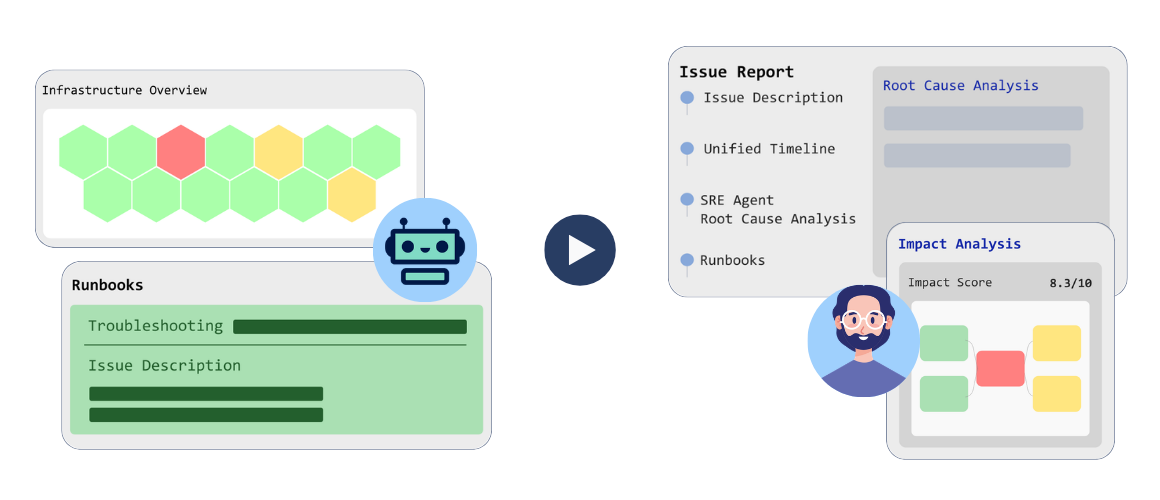






.avif)
.avif)

.png)






.png)
.png)


